Cómo Instalar un LLM local
Tiempo de lectura: 10 minutosUn LLM local es un modelo de lenguaje que se ejecuta en tu propio servidor, sin depender de servicios en la nube. Esta guía explica qué son los principales modelos disponibles (Ollama, DeepSeek, Gemma, Llama), cómo instalarlos paso a paso y por qué un VPS es la opción más práctica para hacerlo.
Si quieres privacidad real, control total y costos predecibles, ejecutar un LLM en tu propio servidor es hoy una alternativa concreta y accesible.
¿Qué es un LLM local y por qué instalarlo?
Un LLM (Large Language Model, o modelo de lenguaje grande) es el tipo de modelo de inteligencia artificial que está detrás de herramientas como ChatGPT, Gemini o Claude. Estos modelos procesan texto, responden preguntas, generan código, resumen documentos y mucho más.
La diferencia entre usar un LLM en la nube y uno local es fundamental: cuando usas ChatGPT, tus consultas viajan a los servidores de OpenAI y son procesadas allí. Cuando instalas un LLM en tu propio servidor, todo ocurre dentro de tu infraestructura, sin que ningún dato salga al exterior.
Esto tiene implicaciones directas para:
- Privacidad: los datos de tus clientes, documentos internos o conversaciones confidenciales no abandonan tu servidor.
- Seguridad: eliminas la dependencia de terceros y los riesgos asociados a filtraciones de proveedores externos.
- Autonomía: no dependes de cuotas, límites de API, cambios de precios ni decisiones de una empresa ajena.
- Costos predecibles: pagas por el servidor, no por cada consulta.
Para desarrolladores, pymes con datos sensibles, abogados, médicos, educadores o cualquier profesional que trabaje con información confidencial, tener un LLM propio no es un lujo técnico: es una decisión estratégica.
Si te interesa profundizar en cómo este tipo de herramientas puede impactar en tu negocio, el artículo sobre cómo implementar la IA en una empresa ofrece un buen punto de partida.
Principales LLM de código abierto: qué es cada uno y quién lo creó
Ollama
Ollama no es un modelo en sí mismo: es una herramienta de gestión que permite descargar, ejecutar y administrar distintos modelos de lenguaje en un servidor Linux, macOS o Windows de forma simple. Es el equivalente a un gestor de paquetes, pero para LLMs. Desarrollada por la empresa Ollama Inc., se ha convertido en el estándar de facto para correr modelos locales gracias a su interfaz de línea de comandos intuitiva y su compatibilidad con docenas de modelos.
Lo que hace Ollama en la práctica: descarga el modelo, lo cuantiza (reduce su tamaño para que consuma menos RAM), lo mantiene en ejecución y expone una API REST en el puerto 11434 para que otras aplicaciones puedan consultarlo.
Meta Llama (Llama 3, Llama 3.1, Llama 3.2)
Llama es la familia de modelos de código abierto desarrollada por Meta (la empresa detrás de Facebook e Instagram). Con el lanzamiento de Llama 2 en 2023 y Llama 3 en 2024, Meta posicionó esta familia como una de las más capaces del ecosistema open source. Llama 3.1 en su variante de 8B parámetros es uno de los modelos más equilibrados para correr en un VPS con 16-32 GB de RAM: ofrece respuestas coherentes, soporte de razonamiento y capacidad para múltiples idiomas incluyendo español.
DeepSeek
DeepSeek es un modelo desarrollado por la empresa china DeepSeek AI, que sorprendió al mundo a principios de 2025 con un rendimiento comparable a modelos propietarios de primera línea, pero con un costo de entrenamiento y ejecución significativamente menor. DeepSeek R1 es especialmente destacable por su capacidad de razonamiento paso a paso, y en su versión destilada (7B o 14B parámetros) se puede ejecutar en hardware modesto sin GPU dedicada.
Para entender en detalle qué es DeepSeek y sus casos de uso, puedes consultar la guía completa sobre DeepSeek que explica sus variantes y diferencias.
Google Gemma
Gemma es la familia de modelos de código abierto de Google DeepMind, lanzada en 2024. A diferencia de Gemini (el modelo cerrado de Google), Gemma está disponible para descarga y uso local. Sus versiones de 2B y 7B parámetros son especialmente eficientes: Gemma 2B puede correr en servidores con apenas 8 GB de RAM y ofrece respuestas de calidad sorprendente para su tamaño. La versión Gemma 2 (9B y 27B) mejoró considerablemente la coherencia y el soporte multilingüe.
Mistral y Mixtral
Mistral AI es una startup francesa fundada en 2023 que se convirtió rápidamente en un referente del ecosistema open source europeo. Sus modelos Mistral 7B y Mixtral 8x7B (una arquitectura de mezcla de expertos o MoE) ofrecen un rendimiento muy por encima de lo esperado para su tamaño. Mistral es especialmente reconocido por su capacidad de seguir instrucciones complejas y generar código.
Microsoft Phi
La familia Phi de Microsoft Research representa una apuesta por modelos pequeños pero altamente capaces. Phi-3 Mini (3.8B parámetros) y Phi-3 Medium (14B) están diseñados para tareas de razonamiento y pueden ejecutarse en hardware con recursos limitados. Son una opción excelente para proyectos que priorizan la eficiencia por encima de la versatilidad.
Comparativa de LLM locales
| Modelo | Creador | Tamaño mínimo recomendado | RAM mínima (VPS) | Razonamiento | Multilingüe | Ideal para |
|---|---|---|---|---|---|---|
| Llama 3.1 8B | Meta | 8B | 16 GB | Alto | Sí | Uso general, español |
| DeepSeek R1 7B | DeepSeek AI | 7B | 16 GB | Muy alto | Parcial | Análisis, lógica |
| Gemma 2 9B | Google DeepMind | 9B | 16 GB | Medio-alto | Sí | Uso general, eficiencia |
| Mistral 7B | Mistral AI | 7B | 16 GB | Alto | Sí | Instrucciones, código |
| Mixtral 8x7B | Mistral AI | 47B | 64 GB | Muy alto | Sí | Tareas complejas |
| Phi-3 Mini | Microsoft | 3.8B | 8 GB | Medio | Parcial | Recursos limitados |
| Gemma 2B | Google DeepMind | 2B | 8 GB | Básico | Parcial | Pruebas, desarrollo |
Nota sobre la columna RAM: estos valores corresponden a la versión cuantizada (Q4) del modelo, que Ollama aplica automáticamente. Sin cuantización, los requisitos se duplican o triplican.
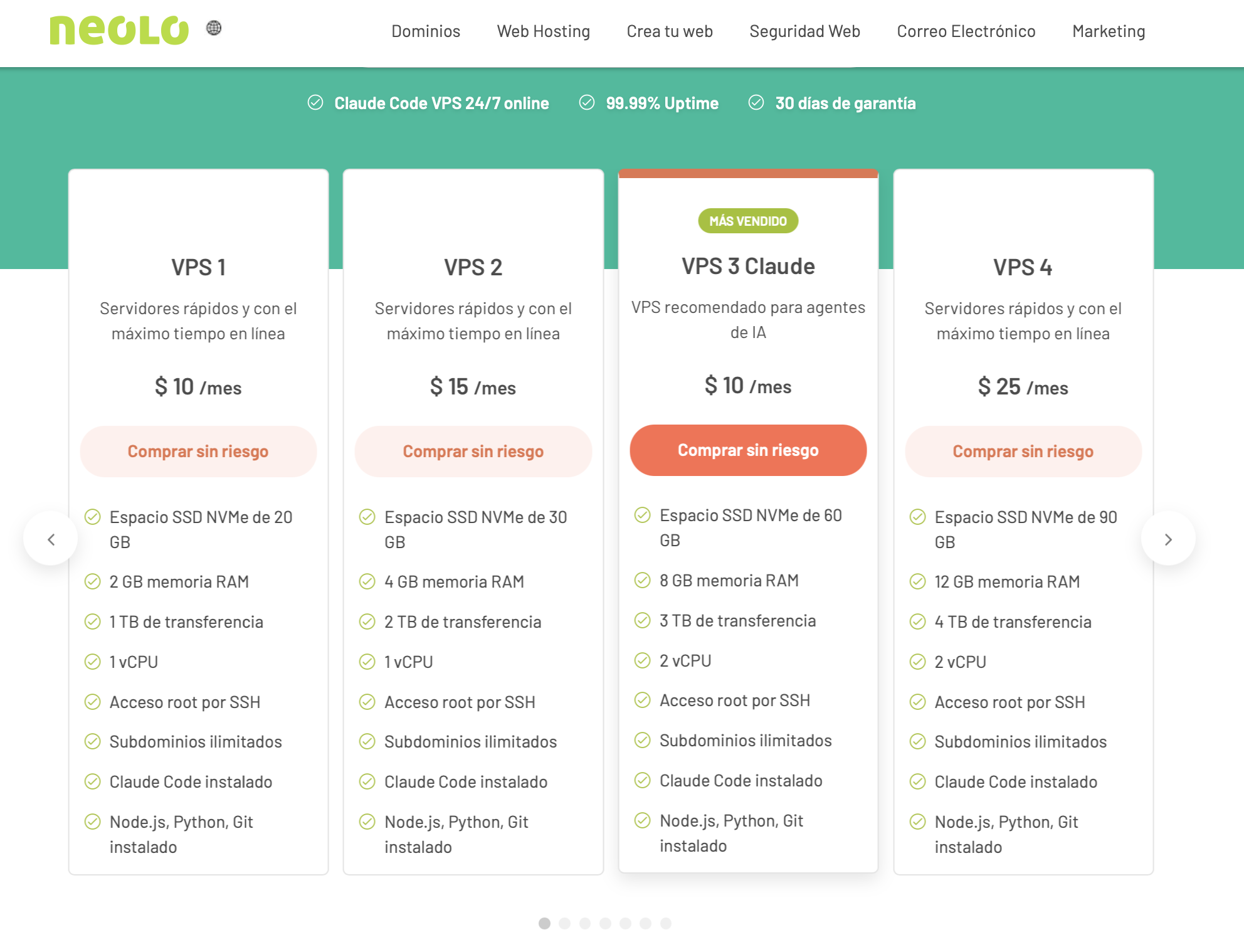
Requisitos para instalar un LLM local en un VPS
Antes de ejecutar el primer modelo, es importante entender qué necesita el servidor.
Sistema operativo
La opción más compatible y documentada es Ubuntu 22.04 LTS o Ubuntu 24.04 LTS. Debian 12 también funciona sin problemas. Se necesita acceso root o un usuario con privilegios sudo.
RAM
Este es el recurso más crítico. La regla práctica es:
- Modelos de 7-9B parámetros (cuantizados): mínimo 16 GB de RAM
- Modelos de 13-14B parámetros: mínimo 32 GB de RAM
- Modelos de 70B parámetros: 64 GB o más, idealmente con GPU
CPU y almacenamiento
Sin GPU, el modelo corre completamente en CPU. Esto es funcional para consultas ocasionales o desarrollo, pero no para alta concurrencia. Un VPS con 4-8 núcleos reales ofrece un rendimiento razonable.
El almacenamiento depende de cuántos modelos se descarguen. Cada modelo pesa entre 4 GB (Phi-3 Mini cuantizado) y 40 GB (Llama 3.1 70B cuantizado). Un disco de 50-100 GB es suficiente para 2-3 modelos medianos.
Conectividad
No se necesita ningún puerto abierto especialmente, a menos que quieras exponer la API de Ollama hacia afuera (lo cual no se recomienda sin autenticación).
Un hosting VPS de Neolo con 16 o 32 GB de RAM cubre sin problemas los requisitos para ejecutar modelos de 7B a 14B parámetros, y es la base sobre la que están pensados los ejemplos de esta guía.
Cómo instalar Ollama en un VPS Linux paso a paso
Los siguientes comandos están probados en Ubuntu 22.04 y 24.04 con acceso root.
Paso 1: Actualizar el sistema
apt update && apt upgrade -y
Paso 2: Instalar Ollama
Ollama ofrece un script de instalación oficial que detecta el sistema y configura el servicio automáticamente:
curl -fsSL https://ollama.com/install.sh | sh
Este script instala el binario en /usr/local/bin/ollama y crea un servicio systemd que arranca automáticamente con el servidor.
Paso 3: Verificar que el servicio está activo
systemctl status ollama
La salida debe mostrar active (running). Si no está activo:
systemctl enable --now ollama
Paso 4: Confirmar que la API responde
curl http://localhost:11434
Deberías ver el texto: Ollama is running
Ollama ya está instalado. Ahora se pueden descargar modelos.
Cómo ejecutar modelos con Ollama: DeepSeek, Gemma, Llama y más
Descargar y ejecutar un modelo
El comando ollama run descarga el modelo si no existe localmente y abre una sesión interactiva:
ollama run llama3.1
Para DeepSeek R1 en su versión destilada de 7B:
ollama run deepseek-r1:7b
Para Gemma 2 de 9B:
ollama run gemma2:9b
Para Mistral 7B:
ollama run mistral
Para Phi-3 Mini (ideal si el VPS tiene 8 GB de RAM):
ollama run phi3:mini
Listar modelos descargados
ollama list
Eliminar un modelo para liberar espacio
ollama rm gemma2:9b
Usar la API REST desde una aplicación
Ollama expone una API compatible con el formato de OpenAI en http://localhost:11434. Para hacer una consulta desde la terminal:
curl http://localhost:11434/api/generate \
-d '{
"model": "llama3.1",
"prompt": "Explica qué es una red neuronal en 3 oraciones.",
"stream": false
}'
Esta API permite integrar el modelo en aplicaciones web, bots de Telegram, pipelines de automatización con n8n o cualquier script que haga peticiones HTTP.
Exponer la API de forma segura con un proxy inverso (opcional)
Si se necesita acceder a Ollama desde fuera del servidor, lo correcto es usar un proxy inverso como Nginx con autenticación básica. No exponer el puerto 11434 directamente a internet.
server {
listen 443 ssl;
server_name ollama.tudominio.com;
ssl_certificate /etc/letsencrypt/live/ollama.tudominio.com/fullchain.pem;
ssl_certificate_key /etc/letsencrypt/live/ollama.tudominio.com/privkey.pem;
location / {
auth_basic "Restringido";
auth_basic_user_file /etc/nginx/.htpasswd;
proxy_pass http://127.0.0.1:11434;
}
}
Esto añade una capa de autenticación antes de llegar al modelo.
Ventajas de instalar un LLM local: privacidad, seguridad y autonomía
Privacidad de datos
Al usar un LLM en la nube, cada consulta puede ser almacenada, analizada o usada para mejorar el modelo del proveedor (dependiendo de los términos de servicio). Con un modelo local, los datos no salen del servidor. Esto es especialmente relevante para:
- Despachos legales que procesan contratos
- Clínicas o consultorios que manejan historiales
- Empresas que trabajan con información financiera confidencial
- Desarrolladores que quieren mantener el código fuente privado
Sin dependencia de terceros
Los servicios de IA en la nube pueden cambiar sus precios, sus políticas de uso, sus límites de velocidad o directamente discontinuar modelos. Un LLM local funciona independientemente de lo que decida cualquier empresa externa.
Costos predecibles
Con un VPS de capacidad adecuada, el costo mensual es fijo. No hay costo por token, no hay sorpresas al final del mes si el equipo usó el modelo intensamente.
Personalización total
Se puede hacer fine-tuning del modelo con datos propios, ajustar parámetros de generación, encadenar múltiples modelos o integrarlos en flujos de trabajo complejos. Algo que no es posible con APIs cerradas.
Disponibilidad sin límites
No hay límites de velocidad, no hay colas en horarios pico, no hay degradación del servicio cuando el proveedor está saturado. El modelo responde mientras el servidor esté en pie.
Si te interesa entender cómo actúan los agentes de IA que puedes construir sobre estos modelos, el artículo sobre cómo actúa un agente de IA explica el funcionamiento interno con claridad.
Errores comunes al instalar LLM locales
El modelo no responde o la descarga se interrumpe
Ollama descarga los modelos en trozos. Si la conexión es inestable, la descarga puede fallar a mitad. La solución es volver a ejecutar ollama run [modelo]: retomará desde donde se interrumpió si el archivo parcial sigue en disco.
El servidor se queda sin RAM y el proceso muere
Esto ocurre cuando se intenta cargar un modelo demasiado grande para la RAM disponible. El sistema operativo termina el proceso sin aviso. La solución es verificar la RAM disponible con free -h antes de descargar el modelo y elegir una versión cuantizada más pequeña.
La API no responde desde fuera del servidor
Por defecto, Ollama escucha solo en 127.0.0.1. Para que escuche en todas las interfaces (necesario si se usa detrás de un proxy), hay que modificar la variable de entorno del servicio:
systemctl edit ollama
En el archivo que se abre, añadir:
[Service]
Environment="OLLAMA_HOST=0.0.0.0:11434"
Luego reiniciar el servicio:
systemctl restart ollama
Recuerda proteger el acceso con el proxy inverso mencionado anteriormente.
El modelo responde muy lento
Sin GPU, la velocidad de generación depende de los núcleos de CPU y la memoria RAM disponible. Un modelo de 7B en un VPS de 4 núcleos genera aproximadamente 5-15 tokens por segundo, lo que es aceptable para uso interactivo pero puede no serlo para alta concurrencia. Si el caso de uso requiere velocidad, la opción es migrar a un servidor con más núcleos o agregar una GPU.
Conflictos de versiones con libc o dependencias del sistema
En sistemas Ubuntu 20.04 o anteriores, Ollama puede fallar por incompatibilidad con versiones de glibc. La solución más directa es usar Ubuntu 22.04 o superior. Si no es posible, se puede ejecutar Ollama dentro de un contenedor Docker.
Lo que dicen los clientes de Neolo
★★★★★ Fernando
«Hace muchos años que tengo web hosting en Neolo, y la verdad es que no tengo interrupciones en el servicio. Nuestras webs están siempre activas, y alguna vez cuando aparece algún inconveniente de origen externo y ajeno a ellos, la gente de Neolo corre a solucionarlo. Excelente servicio recibido, en lo técnico y en lo humano.»★★★★★ Bruno Balzani
«Cliente desde 2009. Neolo lo que tiene es la mejor atención, pero por lejos.»★★★★★ Püertä Öndrëj
«Una empresa comprometida con la calidad, con unos servicios a un costo insuperable.»
Preguntas frecuentes
¿Puedo instalar un LLM local sin GPU?
Sí. Todos los modelos que maneja Ollama pueden correr completamente en CPU. La GPU acelera considerablemente la generación de texto, pero no es imprescindible para uso personal o desarrollo. En un VPS sin GPU, un modelo de 7B genera entre 5 y 15 tokens por segundo, lo que es suficiente para la mayoría de los casos de uso individuales o de equipos pequeños.
¿Qué diferencia hay entre Ollama y ejecutar un modelo directamente con Python?
Ollama automatiza la descarga, cuantización y servicio del modelo. Si se quisiera hacer lo mismo manualmente con librerías como llama.cpp o transformers de Hugging Face, habría que gestionar la conversión de pesos, la configuración del servidor y las dependencias del sistema operativo. Ollama hace todo eso en un solo comando. Para producción, Ollama es la opción más práctica y mantenida actualmente.
¿Cuánto almacenamiento necesito para varios modelos?
Depende de los modelos elegidos. En versión cuantizada Q4 (la que usa Ollama por defecto):
– Phi-3 Mini (3.8B): ~2.3 GB
– Gemma 2B: ~1.7 GB
– Mistral 7B / Llama 3.1 8B: ~4.5-5 GB
– Gemma 2 9B / DeepSeek R1 7B: ~5-6 GB
– Llama 3.1 70B: ~40 GB
Para tener 3-4 modelos medianos, 50 GB de almacenamiento es suficiente.
¿Es seguro exponer la API de Ollama a internet?
No directamente. El puerto 11434 no tiene autenticación por defecto. Siempre se debe usar un proxy inverso con HTTPS y autenticación básica o tokens antes de exponer la API al exterior. Nunca abrir el puerto 11434 directamente en el firewall hacia internet.
¿Puedo usar un LLM local para entrenar o hacer fine-tuning con mis propios datos?
Ollama está orientado a inferencia (usar el modelo), no a entrenamiento. Para fine-tuning se necesitan herramientas como Axolotl, LLaMA-Factory o el ecosistema de Hugging Face PEFT/LoRA. Estos procesos requieren más recursos (especialmente RAM y, en la práctica, una GPU) y están más allá del alcance de esta guía, pero son factibles en un servidor dedicado con las especificaciones adecuadas.
¿Qué modelo recomiendan para español?
Llama 3.1 8B es actualmente el modelo más equilibrado para español en el ecosistema open source: fue entrenado con un corpus multilingüe amplio y ofrece respuestas coherentes en español sin configuraciones adicionales. Gemma 2 9B también funciona bien. DeepSeek R1 tiene capacidades de razonamiento superiores pero su soporte en español es más irregular.
Conclusión
Instalar un LLM local ha pasado de ser un ejercicio técnico para investigadores a una opción real para cualquier equipo o profesional que valore la privacidad, la autonomía y los costos predecibles. Con Ollama como gestor y modelos como Llama 3.1, DeepSeek R1 o Gemma 2, es posible tener un asistente de IA completamente propio funcionando en menos de una hora.
El único requisito real es contar con un servidor con suficiente RAM. Para eso, el hosting VPS de Neolo es una opción especialmente adecuada: lleva más de 20 años en el mercado, responde el 80% de las consultas en menos de una hora y ofrece garantía de reembolso de 30 días, por lo que puedes probar la configuración sin riesgo. Para proyectos que combinan LLMs locales con flujos de automatización, también puedes revisar el artículo sobre cómo alojar un LLM en un VPS para profundizar en aspectos de configuración avanzada.